
Unity 性能优化汇总
渲染优化
静态批处理
将静态(不移动)的物体合并为一个大网格,减少DrawCall(需标记为Static)。
原理
标明为 Static 的静态物件,如果在使用相同材质球的条件下,在Build(项目打包)的时候Unity会自动地提取这些共享材质的静态模型的Vertex buffer和Index buffer。根据其摆放在场景中的位置等最终状态信息,将这些模型的顶点数据变换到世界空间下,存储在新构建的大Vertex buffer和Index buffer中。并且记录每一个子模型的Index buffer数据在构建的大Index buffer中的起始及结束位置。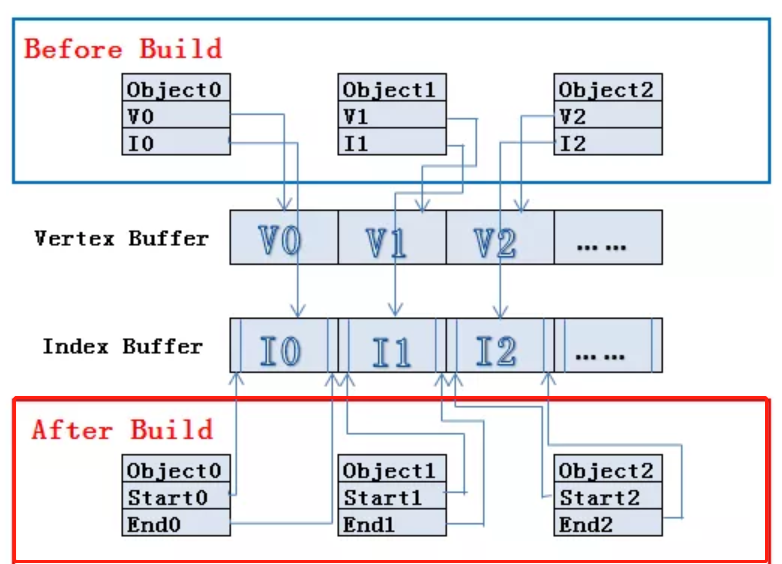
前提条件
标记为 Static:物体必须在 Inspector 窗口勾选 Static 标志(至少勾选 “Static” 或 “Batching Static”)。
不可移动:静态批处理的物体在运行时不能移动、旋转或缩放,否则会破坏批处理效果。
相同材质:合并的物体必须使用相同的材质(Shader 和材质属性需一致)。如果材质实例不同(即使参数相同),批处理可能失败。
顶点限制:单个批次的合并网格顶点数不能超过目标平台的限制(例如 OpenGL ES 为 64k 顶点,其他平台通常为 48k)。
实现流程
步骤 1:预处理阶段(构建时)
Unity 在构建项目时(或进入运行模式时)会扫描所有标记为 Static 的物体。
将这些物体的网格数据合并成一个或多个更大的“批处理网格”(Batch Mesh)。合并过程包括:
合并顶点、法线、UV 等数据。
调整每个子网格的变换矩阵,使其在合并后保持正确的世界空间位置。
步骤 2:渲染阶段(运行时)
合并后的网格会被一次性提交到 GPU,通过 单个 Draw Call 渲染所有合并的物体。
每个物体的材质属性(如颜色、纹理偏移)通过 材质属性块(MaterialPropertyBlock) 或 GPU Instancing(需显式启用)动态传递,避免材质实例分离。
动态批处理
Dynamic batching的原理也很简单,在进行场景绘制之前将所有的共享同一材质的模型的顶点信息变换到世界空间中,然后通过一次Draw call绘制多个模型,达到合批的目的。
模型顶点变换的操作是由CPU完成的,所以这会带来一些CPU的性能消耗。并且计算的模型顶点数量不宜太多,否则CPU串行计算耗费的时间太长会造成场景渲染卡顿,
所以Dynamic batching只能处理一些小模型。
Dynamic batching在降低Draw call的同时会导致额外的CPU性能消耗,
所以仅仅在合批操作的性能消耗小于不合批,Dynamic batching才会有意义。
而新一代图形API( Metal、Vulkan)在批次间的消耗降低了很多,
所以在这种情况下使用Dynamic batching很可能不能获得性能提升。
Dynamic batching相对于Static batching不需要预先复制模型顶点,
所以在内存占用和发布的程序体积方面要优于Static batching。但是Dynamic
batching会带来一些运行时CPU性能消耗,Static batching在这一点要比Dynamic batching更加高效。
动态批处理条件
相同材质:所有对象必须使用相同的材质和纹理。
相同Shader:Shader 必须相同,且不支持多 Pass Shader。
顶点数量:单个对象的顶点数不能超过 300 个(默认值,可通过 Dynamic Batching 设置调整)。
相同渲染队列:所有对象必须在同一渲染队列中。
对象状态:动态批处理仅适用于非静态对象,静态对象使用静态批处理。
相同缩放:对象的缩放比例必须一致。
GPU实例化
对大量相同模型(如植被、建筑群)使用GPU实例化,共享网格和材质但允许变换差异,显著减少DrawCall。
遮挡剔除(Occlusion Culling)
通过烘焙剔除不可见物体,减少渲染负载。
贴图集(Texture Atlas)
合并多个小纹理为一个大图集,减少材质切换次数。
LOD(层级细节)
根据物体与摄像机的距离切换不同精度的模型,远距离使用低面数模型减少Tris(三角形数)。
光照优化
使用烘焙光照(Lightmapping)替代实时动态光,降低运行时计算量。
减少动态光源数量,优先使用光照探针(Light Probes)。
资源优化
纹理与模型
纹理压缩:移动端使用ETC(安卓)或PVRTC(iOS)格式,避免DXT5导致CPU解压占用15。
关闭Read/Write Enabled:禁用纹理的CPU可读选项,避免内存双倍占用115。
模型简化:动态模型面片数<3000,静态模型顶点数<500。
内存管理
资源分离打包:公共资源(如字体、贴图)单独打包,避免冗余加载。
异步加载:使用Addressables或AssetBundle异步加载资源,避免卡顿27。
音频优化
背景音乐使用压缩格式(如MP3),短音效使用非压缩格式(如WAV)以减少解码开销13。
脚本与逻辑优化
使用合适的属性进行优化
[MethodImpl(MethodImplOptions.AggressiveInlining)]
频繁的数学操作可以用 SIMD 进行优化
避免高频操作
减少Update调用:将非必要逻辑移至Start或协程,或通过Time.frameCount % interval限帧执行19。
缓存组件引用:避免在Update中频繁调用GetComponent或Find,改为在Start中预存19。
对象池技术
对频繁创建/销毁的对象(如子弹、粒子)使用对象池,复用实例减少GC压力267。
减少垃圾回收(GC)
避免字符串拼接(改用StringBuilder),减少装箱操作(如避免将值类型转为object)17。
禁用LINQ(因产生大量临时对象)1。
UI优化
UI 性能优化有许多,具体可以查看这篇文章。
工具与调试
性能分析工具
Unity Profiler:监控CPU、GPU、内存等指标,定位瓶颈(如高DrawCall或GC峰值)49。
Frame Debugger:逐帧分析渲染流程,查看批处理与剔除效果311。
内存泄漏排查
使用Profiler的内存快照功能,检测未释放资源或脚本引用残留711。
进阶策略
多线程与Job System
将物理计算、动画等耗时操作移至子线程,或使用ECS(实体组件系统)架构提升并行效率11。
Shader优化
简化复杂数学运算(如避免discard操作),减少变体数量以降低编译开销。




